In this post we will go through using the tmdb api to gather film information and save it in a dataframe. For more information check out the documentation here.
The first thing needed is to obtain a api key. Anyone with a tmdb account can obtain a key from their account setting page.
Now that you have an api key, it is time to download tmdbsimple. Tmdbsimple is a wrapper that simplifies the code needed to access the information in the api. To learn more about tmbdsimple check out the github repo here. Tmdbsimple can be pip installed through your terminal by typing “pip install tmdbsimple”.
Now that we have our api key and tmdb simple, we can start looking at the tmdb api.
We imported the necessary libraries and started the api session so we can decide which films we want to gather the information for. We are going to use a selection of movies that were scraped from Letterboxd. The dataframe that we are loading in already has the film names, tmdb ids and directors. We are aiming to add the genres, languages, run time, tag line, synopsis, and average rating from the api.

<class 'pandas.core.frame.DataFrame'>
RangeIndex: 71928 entries, 0 to 71927
Data columns (total 7 columns):
film_name 71872 non-null object
lb_id 71928 non-null int64
lb_link 71928 non-null object
tmdb_id 71928 non-null int64
movie_tv 71928 non-null object
Year 71927 non-null object
Director 71909 non-null object
dtypes: int64(2), object(5)
memory usage: 3.8+ MB
None
For the sake of time, we are just going to take the first 150 films from the dataframe.

<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 7 columns):
film_name 150 non-null object
lb_id 150 non-null int64
lb_link 150 non-null object
tmdb_id 150 non-null int64
movie_tv 150 non-null object
Year 150 non-null object
Director 150 non-null object
dtypes: int64(2), object(5)
memory usage: 8.3+ KBSince we are only looking for movie information, we need to quickly check that all the rows in the dataframe are actually movies and not tv shows.

movie 150
Name: movie_tv, dtype: int64Before we continue with adding information to the dataframe, let’s take a quick look at what the api information will look like and make sure we can actually gather all the data.
Lets just look at the first film in the dataframe, Parasite. We see that the movie’s imdb_id is 496243.

{'adult': False,
'backdrop_path': '/TU9NIjwzjoKPwQHoHshkFcQUCG.jpg',
'belongs_to_collection': None,
'budget': 11363000,
'genres': [{'id': 35, 'name': 'Comedy'},
{'id': 53, 'name': 'Thriller'},
{'id': 18, 'name': 'Drama'}],
'homepage': 'https://www.parasite-movie.com/',
'id': 496243,
'imdb_id': 'tt6751668',
'original_language': 'ko',
'original_title': '기생충',
'overview': "All unemployed, Ki-taek's family takes peculiar interest in the wealthy and glamorous Parks for their livelihood until they get entangled in an unexpected incident.",
'popularity': 137.913,
'poster_path': '/7IiTTgloJzvGI1TAYymCfbfl3vT.jpg',
'production_companies': [{'id': 4399,
'logo_path': '/7bWmbWfxFNSGTCjLHkHn3UjspZS.png',
'name': 'Barunson E&A',
'origin_country': 'KR'},
{'id': 7036,
'logo_path': '/javbyY0ZCvlFJtly3tpZqf2NwLX.png',
'name': 'CJ Entertainment',
'origin_country': 'KR'}],
'production_countries': [{'iso_3166_1': 'KR', 'name': 'South Korea'}],
'release_date': '2019-05-30',
'revenue': 257591776,
'runtime': 133,
'spoken_languages': [{'english_name': 'English',
'iso_639_1': 'en',
'name': 'English'},
{'english_name': 'German', 'iso_639_1': 'de', 'name': 'Deutsch'},
{'english_name': 'Korean', 'iso_639_1': 'ko', 'name': '한국어/조선말'}],
'status': 'Released',
'tagline': 'Act like you own the place.',
'title': 'Parasite',
'video': False,
'vote_average': 8.5,
'vote_count': 11273}Above we can see all the information the api has to offer for each movie. We can isolate certain information below:

'Parasite'
"All unemployed, Ki-taek's family takes peculiar interest in the wealthy and glamorous Parks for their livelihood until they get entangled in an unexpected incident."
133
8.5
'Act like you own the place.'Language and genre will require a little more work to isolate. If you just called language you wouldn’t get what we are looking for.

[{'english_name': 'English', 'iso_639_1': 'en', 'name': 'English'},
{'english_name': 'German', 'iso_639_1': 'de', 'name': 'Deutsch'},
{'english_name': 'Korean', 'iso_639_1': 'ko', 'name': '한국어/조선말'}]We will work though making a for loop to pull out the languages.

['English', 'en', 'English']
'English'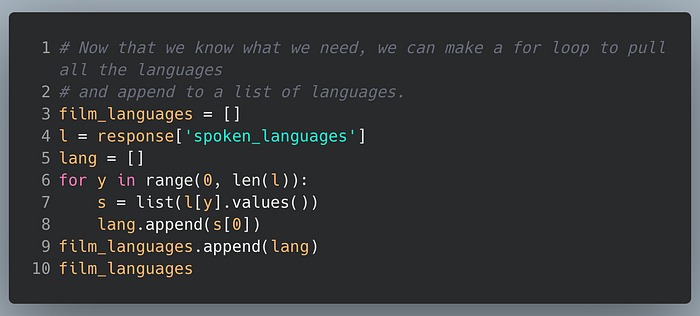
[['English', 'German', 'Korean']]The same process can be done to extract the genres.

[['Comedy', 'Thriller', 'Drama']]Now that we have all that worked out, we put it all together in a for loop.
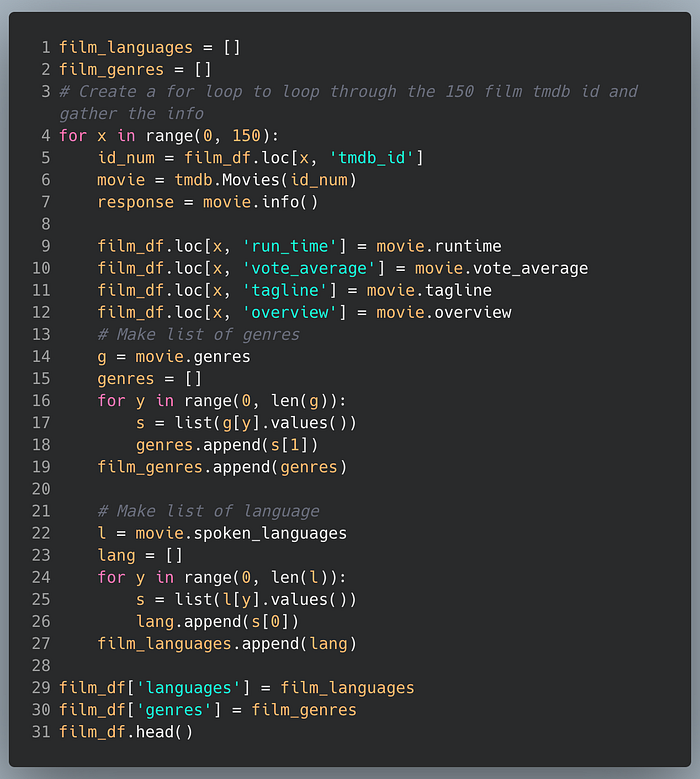

Last thing we are going to do is quickly check that there are no null values in film_df.

<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 13 columns):
film_name 150 non-null object
lb_id 150 non-null int64
lb_link 150 non-null object
tmdb_id 150 non-null int64
movie_tv 150 non-null object
Year 150 non-null object
Director 150 non-null object
run_time 150 non-null float64
vote_average 150 non-null float64
tagline 150 non-null object
overview 150 non-null object
languages 150 non-null object
genres 150 non-null object
dtypes: float64(2), int64(2), object(9)
memory usage: 15.3+ KBNow we have a dataframe with all the information we wanted from the tmdb api. Later we can expand it for the entire 77,000 films we have in the original dataframe.
